
Content is inherently diverse, written for and understandable only by a specific audience, often multilingual, scattered across silos and different systems, and regularly ambiguous and therefore difficult to understand. Even humans, who are actually experts at understanding natural language, regularly get lost in Babylonian language confusion.
On one and the same topic or business object, there are always numerous perspectives on how to look at it and talk and inform about it. Therefore, for example, a product is broken down into individual aspects, and accordingly there are then technical documents, marketing content, legal information, social media content, or reports and knowledge documents for each object, stored in different silos, languages and versions.
However, these content building blocks are rarely linked and thus create their own, sometimes even contradictory, realities. Clearly, not all content is meant to be useful to everyone. But customers and employees are experiencing increasing pressure to get to relevant information quickly, while not overlooking anything and gaining a complete overview.
For computers and machine learning algorithms, truly understanding the content of a text is no easy task. And for both humans and machines, it is an even greater challenge to link disparate content from different systems and formats in such a way that what actually belongs together can also be understood and experienced as a whole. In plain language: We have created countless data silos, and with them a systemic crisis.
This also means that digital content, as currently developed and accessible in a typical CMS, cannot be used efficiently for automated decision making or knowledge discovery, nor can it be the central driver of a truly great customer experience on the front end.
What’s always missing is information about the context in which the content is embedded. The metadata and background knowledge are needed, as well as additional facts about things and topics that occur in the respective text. Actually, another database would be required, which every CMS should be able to access at any time, so that cross-links and connections to other content can be generated automatically, and this in a continuous and consistent manner.
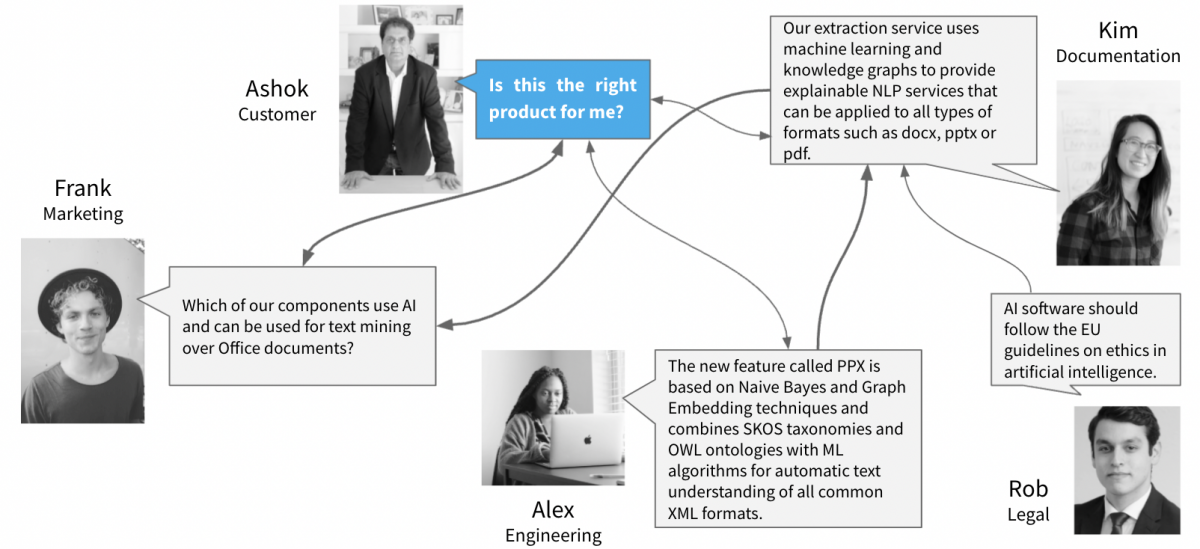
Here's an example: Frank, who works for Marketing, wants to write a blog post and is trying to gather information about a fairly new feature of one of their products. He types a question into the help system, but can't find any answers. Why is that? Frank writes, "Which of our components use AI and can be used for text mining over Office documents?" but none of the terms and words he uses to describe his information needs are used in technical documentation, but just semantically related terms. Actually, the answer to Frank's question would be included in Kim's descriptions (like "Our extraction service uses machine learning and knowledge graphs to provide NLP services that can be applied to all types of formats such as docx, pptx or pdf”). But Frank uses a different vocabulary and expresses facts as a marketing professional in a different language than colleagues in other departments.
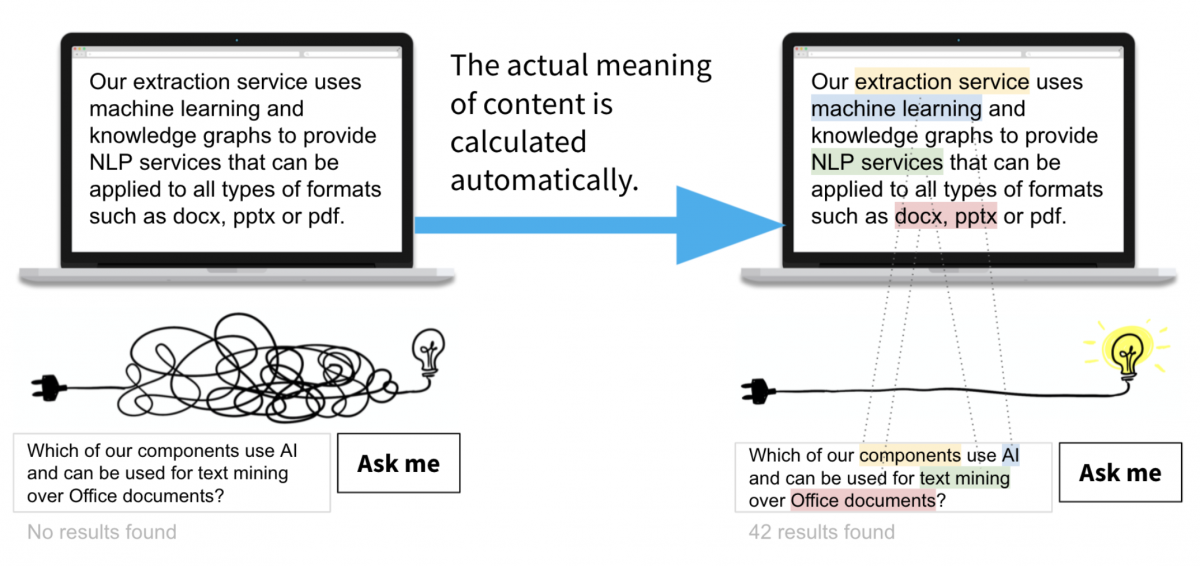
Semantically, there is a great deal of correspondence between what Frank is asking and what Kim, who works as a technical writer, has described. And in doing so, Kim has actually already done excellent translation work when she got the information from Alex, the Head of Software Engineering, that "the new feature called PPX is based on Naive Bayes and Graph Embedding techniques and combines SKOS taxonomies and OWL ontologies with ML algorithms for automatic text understanding of all common XML formats."
You can see it in all companies: Digital content as a vehicle for knowledge transfer only works if everyone involved is at the same level of knowledge and uses vocabularies that are "connectable" to each other, and even then misunderstandings occur again and again. Every role and every person in a company has different background knowledge and ultimately pursues different sub-goals, and so content is understood, interpreted and linked differently.
At the end of the day, what matters is that the information reaches the customer, who more or less always asks the same question in different variations and manifestations: "Is this the right product for me?"
It's the ultimate challenge of any content professional: technical, often very specific knowledge is translated into marketing content and documentation, and must ultimately reach the right target groups at the right time in the best possible personalized way. So how can you optimize these information flows?
What is the way out, and why does our terminology management or the existing search engine not help us?
Knowledge about a subject area (so-called "domain knowledge") essentially comprises these four levels, and can be made available to humans and machines as standard-based semantic knowledge models:
Back to the example with Frank and Kim: Both are talking about a thing called PPX that has been categorized as a feature of a new component, although Frank doesn't know the name yet and is just formulating a placeholder in his question. Frank talks about "AI", which means "Artificial Intelligence", while Kim mentions various ML methods (and you also need to know that ML is short for Machine Learning). So the missing link here is the knowledge that ML is a subset of AI, so semantically very closely related. The same is true for text mining and NLP, which are closely related. Furthermore, there must be the knowledge that, for example, docx or pptx documents are XML-based documents and are commonly referred to as "office documents".
Only when we know all this, we can establish a semantic connection between Frank's question and answers from the technical documentation, written by Kim. Domain experts can do this with both hands tied, but machines and classic text-mining algorithms regularly fail to make this semantic link. This is also where most terminology management systems fall short, as it is not knowledge about things and topics per se that is modeled, but instead a focus is put on nomenclature and translation. But what if this domain knowledge could be transferred to a structured database (aka “knowledge graph”) and from now on always does its job quasi in the background by creating these links fully automatically?
The solution to this well-known problem has been developed over the last 20 years and has a name: Semantic Web. While Google & Co. started to adopt these standards to improve their search several years ago, more and more companies are now using exactly this technology for their own use within their organizations.
"Knowledge Graph" is the new name for this approach, and it helps to efficiently incorporate domain knowledge into virtually any database or content repository. The results are promising: content components can be more easily and dynamically reused, automatically analyzed for various quality attributes, found more quickly, and recommended to users in a personalized way.
These principles can be applied to many business-critical processes, shortening cycle times with lower error rates and also supporting strategic initiatives such as the Learning Organization or Enterprise 360. How you approach the matter, what role taxonomies, ontologies or machine learning play in the process, is something our top experts at the Semantic Web Company can show you step by step.
Get the real thing, download our White Paper and start with a quick Knowledge Graph Assessment here.
